Basic
- If we draw marbles from a bag without replacement then
- If the order matters, it is Permutation.
- If the order does not matters, it is Combination.
LOOK we divide by because among themselves how they sit around does NOT matter! See this visualiser
- When we test a probability based on information we already have in our hand is Conditional Probability.
- Probability of me staying hungry tomorrow is less than I will stay hungry given I have lot of food at home!
- So we shrink our sample space to the particular event.
- Instead of checking how often I am hungry, we check, only those days when I had food in my fridge!
- I love the following visualisation for the math.
Random Variables & Distribution
- There are weird random events. Welp mostly are philosophical and literal. Assume we humanly assign numbers to those random events. Then those number is our Random Variable
- Random Variable are of two types
- Discrete -> Like 1 apple, 2 oranges, 3 girls. Mass function is while cumulative function
- Continuous -> Height, temperature, volume. Density function , while cumulative function is still . Note how for a single point in continuous functions, the probability is just 0.
- In long term the average of independent outcomes of a random variable is its Expectation. It is an essence of the centre value of the distribution
- Precisely the Probability-weighted sum of all possible values of a random variable
- The Variance is the spread of the RV from it’s centre.
- Consequently we might need to compare two random variables and we do it with Covariance i.e. how they behave mutually.
- Some properties of Expectation
- Linearity
- Mean
- Some properties of Variance
- Scaling & constant
- Two variables i.e. if they are independent covariance is 0.
- Many variables
- Sample mean
- Some properties of Covariance
Discrete Distributions
- Bernoulli
Mean is , Variance is .
2. Binomial
Sum of n independent Bernoulli random var.
Mean is , Variance is .
3. Geometric
It counts the number of trails that is required to observe single success.
Where Mean is , Variance is .
4. Poisson
It counts the number of evens occurring in a fixed interval of time or space with a given average rate
Mean and Variance both is is .
Continuous Distributions
- Uniform
When all the possible intervals have equal possibility of happening.
Mean is , Variance is
2. Normal
The normal (or Gaussian) is a distribution which is assumed to be additively produced by many many small effects
Mean is , Variance is .
3. Exponential
It is the continuous analogue of the geometric distribution.
Mean is , Variance is
- The Central Limit Theorem states that the sample mean of a sufficiently large number of independent and identically distributed random variables is approximately normally distributed
Estimation
- Sometimes when we obviously cant calculate a parameter, or guess its underlying distribution say a mean or something of the whole population one by one, we invent a way to Estimate them. And we create the Estimator in such a way so that it is very consistent to the actual parameter if we ever could actually measure that.
- To build estimator around sampled points then using sample mean, sample variances and other sample parameters to estimate the original thing. etc.
- In contrast to point estimation, we measure a range of possible values where the estimator will surely lie in calling it Confidence Interval
- Assume we take sample points from a distribution which we don’t know yet. Then we take an confidence level of then our confidence interval would be i.e. if we measure the sample mean, the actual mean might or might not be in the interval.
- Funnily if we keep taking trials and compare if it does EXIST in the interval or DOES NOT exist compared to total time. YES! PROBABILITY. We see the probability that the interval contains the actual parameter converges to .
- Hence, is a probability measure of the existence of the true parameter in the confidence interval.
- Now there can be two or more estimator for one single parameter, how do we know which one is good.
- There exist computation technique called Bootstrap. We take sample and create an estimator -> Then we take a sample from that sample itself and compare over many iteration of resampling and see if the estimation is consistent.
Bayesian
-
Bayesian probability is a degree of belief.
-
“Expert says there is 60% prob someone will win in election” -> we cannot have many election to make calculation!
-
We cannot always think of long run frequency to test probability because it might not happen in reality.
-
FREQUENTIST: when a coin is flipped infinite times -> half will be heads BAYESIAN: its equally likely for next flip to be head or tails
If we flip one coin and hide the result, what is the probability THIS COIN is head? BAYESIAN: same. FREQUENTIST: no idea.
-
FREQUENTIST CONFIDENCE INTERVAL: We have a formula, if we repeatedly run this, 95% time its correct! BAYESIAN CREDIBLE INTERVAL: Based on everything we know, there is 95% probability that the measure is in this interval.
-
Bayes’ Theorem
Intuitively what proportion when B happens then A happens as well is equal to what proportion of A happens when B happens
- The plausibility of a parameter given the observed data is called likelihood . i.e the probability of has been true value and overlapped with observed in a frequentist mindset.
- The core belief is “the prior belief should be updated as new data is acquired”
Regression
- Least square method is one approach where we compare square of the difference of the two kind of measurements and we try to minimise the sum of the square Equation of line is , After solving for least square we find the solution of intercept and slope with:
Where is sample size, & are the value of the two measurements. is slope and is intercept.
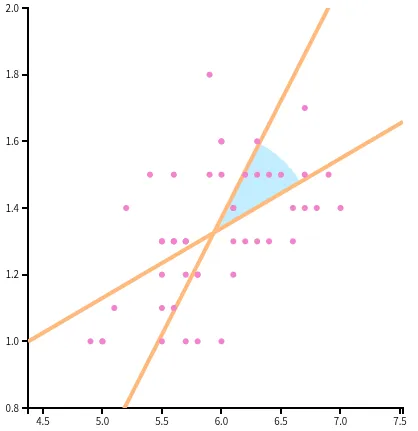
- Now after finding the middle most line that separates the proportionality between the two measurement, we need a rigorous measure to compare if they increase or decrease together or what. We bring Correlation where,
and are defined as:
note, r lies between -1 and 1, and 0 means no correlation. It is actually intuitively, cosine of the angle between when we take the regression lines made by least square i.e the line of wrt to , and i.e the line of wrt to .
Comparison
- Cohen’s d is standardised way to test how big the difference is.
Hypothesis Testing
-
We create a hypothesis to fight two independent concept. Data gives evidence hypothesis is wrong -> we reject the hypothesis Data similar but not same -> fail to reject
Hypothesis could have been anything based on different sample. So we take the trivial case of assuming, there is no difference between the two concept. This is called the Null Hypothesis . We also take an Alternative Hypothesis where we just assume there exists a difference and we fight those two hypothesis together.
-
We put our need as and test with contradiction method assuming is true then, because the two measurement have no difference because the outcome are not supposed to have any differences! So consequently since the individual tests are just bernoulli intuitively we can say using the CLT,
-
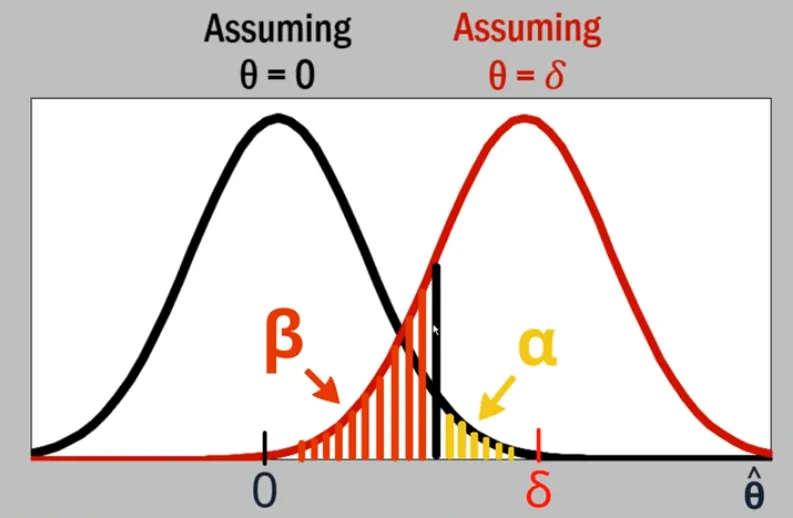
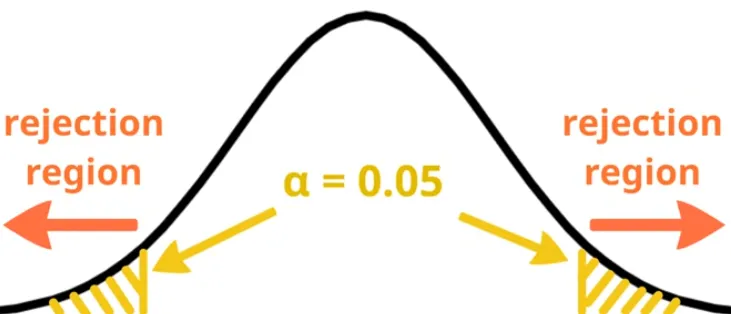
But since normal distribution is continuous , we must define an interval within which we accept the null hypothesis; otherwise, even very small differences could lead us to reject it. The size of probability for which we must reject the is called the level of significance
-
T-Statistics
Consider the test statistic
then we see, , i.e The critical value i.e. the value at the edge of the level of significance is mostly given and with our sample we only calculate to test if the can be rejected or not.
- Nothing can be ever proven it can only be inferred.
- If is true, then if we do the same experiment repeatedly, the test statistics will vary. The probability under that null distribution, of getting a test statistics at least as far from the null value which we observed.
- We always test against both are same, now we reverse ask, for what kind of differences there wouldn’t be much separation? So, we have , And we can also compute for 95% confidence we need, such that where our assumed is 0.05%, by using the normal distribution function we can calculate , so if we use these information,
e.i. the confidence interval of 95% is .
- Power is the probability of rejecting a FALSE i.e. the ability of a model to detect a specified difference,
| Accept | Reject | |
|---|---|---|
| is true | True -ve 1- | False +ve Type I error |
| is false | False -ve Type II error | True +ve Power |